Load files: What are they? And do we still need them?
Takeaway: Load files connect the data you see (PDFs, Word documents, emails, etc.) to behind-the-scenes ‘databases’ that you don’t see. You’ll need them when transferring eDiscovery productions between different applications, but they can be tricky to use. So, try to find eDiscovery software that can handle all kinds of load files.
Attorneys work with eDiscovery data. But computers work with behind-the-scenes ‘databases’.
Data is usually disorganized and in multiple formats (PDF, TIFF, MS Office, emails etc). Think of it as a shopping basket filled with apples, oranges, bananas and limes. A database, on the other hand, is very rigidly structured. You can’t just drop data anywhere you like in a database. Databases have specific slots, called ‘fields’, into which data is inserted. Just as you can’t put a square peg into a round hole, only corresponding pieces of data can enter the field. So, think of databases as a computer’s organized summary of a user’s disorganized data.
‘Load files’ connect data and databases.
A load file is a specifically structured text file. It contains information that connects the things you see in a document and their corresponding slots in a database. Usually, the text in a load file is ‘computer speak’, but sometimes it’ll connect regular text. For example, when you scan a document, optical character recognition (OCR) converts the ‘image’ of the document into computer-readable text. A load file will connect the original image with the converted text.
Load files seem like gibberish to the average human user, but they’re very useful for a computer.
If you open a load file in a text editor, you may see a block of text like in the image below. This block contains crucial information about a document, and the block is repeated over and over again (with different data) until each file in your case has a block of its own.
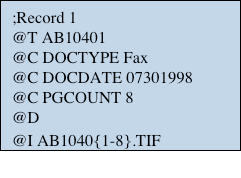
Load files are useful because they distribute information into different slots (or ‘fields’).
In the snippet above, the DOCTYPE field tells the database that the document in question was originally a fax. The PGCOUNT field tells the database that the document is 8 pages long. The ‘I’ field tells the database the name of the file. And so on. As you can see, the information is very specific and only certain identifiers make sense in certain slots. For example, it wouldn’t make sense to say the page count is ‘FAX’.
Load files are still very useful, but we don’t use them as much as we did a decade ago.
Technology has changed a lot since the early 2000s, and load files don’t lie at the centre of eDiscovery anymore.
Nowadays, we don’t need load files to upload files into eDiscovery software.
Older databases were designed to deal with slow computers and limited storage space. Nowadays, with Cloud computing, speed and storage aren’t an issue anymore. So, databases have evolved. New NoSQL (pronounced ‘No Sequel’) databases are built to work without load files – which simplifies eDiscovery.
But we do still need load files when sharing productions.
You won’t need load files when using files in a particular eDiscovery application. But you’ll need them if your data has to move from one application to another. It turns out that they’re still the common language that all these applications speak. So, if opposing counsel doesn’t use the same eDiscovery software as you, they’ll need to send a load file along with their production.
Here are two important things you have to keep in mind when dealing with load files.
1. Choose eDiscovery software that automatically detects and applies load files.
All load-file productions aren’t structured identically, which can make it hard for your software to use them. For example, sometimes they’ll have a main directory with a bunch of folders for load files, images, natives, and text files. At other times, these folders won’t sit in the main directory and will be part of multiple sub-directories instead. So, to decipher a load file’s data, your eDiscovery software will need to be able to process all these variations, automatically.
2. ‘Native’ and ‘PDF’ load file productions are better than TIFF productions.
You can produce your files in 3 different ways:
- Keep them in their native format: Each application you use creates files in a particular ‘format’ – which means it structures the file’s data in a specific way. So, for example, Microsoft Word creates DOCX files (a file with a ‘.docx’ extension). That extension is unique to Word. And it tells your computer to use Word to open the file. This is the ‘native’ format of the file. I.e., the format in which it was originally created.
- Convert native files into TIFFs: The Tagged Image File Format (TIFF) was developed in the mid-1980s by the Aldus Corporation. It was created as a file format to store scanned images. And it was revolutionary because TIFFs are standardized files you can open on any computer. Most operating systems come with a TIFF viewer. But the TIFF format hasn’t been updated since 1992.
- Convert native files into PDFs: The Portable Document Format (PDF) is a newer version of the ‘open on any computer’ TIFF concept. Adobe created it in 1993 and they update it regularly. You’ll need Adobe Acrobat Reader to open PDFs, but can download it for free from Adobe’s website.
Note: We’ve already written posts comparing native files vs PDFs and PDFs vs TIFFs, so do check those out.
As a rule of thumb, try to ask for ‘native’ load file productions.
Native files come with valuable metadata, so a native load file production will be the most useful. But if you can’t get one, here are your other choices, arranged from most to least desirable.
- Native load file production
- A loose collection of native files
- PDF load file production
- A loose collection of document-based PDFs
- TIFF load file production
- Bulk PDF production
- A loose collection of TIFF images
This post might have you thinking that load files are tricky to use. But that problem goes away if you get the right eDiscovery software.
If you’re looking for eDiscovery software that can handle load files, try GoldFynch. It’s an easy-to-use eDiscovery service that’s perfect for small- and midsize law firms and companies.
- It costs just $27 a month for a 3 GB case: That’s significantly less than the nearest comparable software and hundreds of dollars cheaper than many others. With GoldFynch, you know what you’re paying for exactly – its pricing is simple and readily available on the website.
- It’s easy to budget for. GoldFynch charges only for storage (processing is free). So, choose from a range of plans (3 GB to 150+ GB) and know up front how much you’ll be paying. It takes just a few clicks to move from one plan to another, and billing is prorated – so you’ll pay only for the time you spend on any given plan. With legacy software, pricing is much less predictable.
- It takes just minutes to get going. GoldFynch runs in the Cloud, so you use it through your web browser (Google Chrome recommended). No installation. No sales calls or emails. Plus, you get a free trial case (0.5 GB of data and processing cap of 1 GB), without adding a credit card.
- It’s simple to use. Many eDiscovery applications take hours to master. GoldFynch takes minutes. It handles a lot of complex processing in the background, but what you see is minimal and intuitive. Just drag-and-drop your files into GoldFynch and you’re good to go. Plus, it’s designed, developed, and run by the same team. So you get prompt and reliable tech support.
- It keeps you flexible. To build a defensible case, you need to be able to add and delete files freely. Many applications charge to process each file you upload, so you’ll be reluctant to let your case organically shrink and grow. And this stifles you. With GoldFynch, you get unlimited processing for free. So, on a 3 GB plan, you could add and delete 5 GB of data at no extra cost – as long as there’s only 3 GB in your case at any point. And if you do cross 3 GB, your plan upgrades automatically and you’ll be charged for only the time spent on each plan. That’s the beauty of prorated pricing.
- Access it from anywhere. And 24/7. All your files are backed up and secure in the Cloud.
For related posts about eDiscovery, check out the following links.
- eDiscovery Overload: What to Do When Your Small Law Firm Has Too Much to Handle
- 5 eDiscovery Trends Your Small Law Firm Can’t Afford to Miss
- Have You Optimized eDiscovery to Retain Clients for Your Small Law Firm?
- 5-Minute eDiscovery: How to Save Time and Money for Your Small Law Firm
- [Uncovered] eDiscovery Myth: Small Law Firms Can’t Handle Large Cases [over 100 GB]
- 16 Have-to-Know Questions to Simplify eDiscovery for Your Small Law Firm
- 8 Common eDiscovery Mistakes Your Small Law Firm May be Making
- What’s the Difference Between PDF, DOCX, TXT, RTF, files in eDiscovery
- 6 Email eDiscovery File Types (Must Know): PST, MSG, EDB, OST, EML & MBOX