What Are Native Files in eDiscovery and Why Should My Law Firm Care About Them?
Learn how changing a file from its native format can affect the production process and govern the way your small law firm collects data from clients.
What is a native file?
Every digital file is assigned a ‘format’ which indicates how its information is structured. Depending on the format, different programs will process the file data (content) and allow you to access and interact with the content in the operating system. A ‘native’ file format is the original format in which the file was first created.
The native format is (usually) also the one which an application uses to save the file. For example, if a document is created in Microsoft Word, by default it would be in the ‘docx’ format (or the ‘doc’ format if it was created before 2007 when the ‘docx’ format replaced ‘doc’ as the standard format.) It is, however, possible to save a Word document to other file formats (exporting it) or convert it using a third-party program, while still allowing the information to be accessible and alterable. Word files can be converted to PDF or Open Office files (.odt), which can then be edited using programs like Adobe Acrobat and Apache Open Office.
Where do native files fit in with eDiscovery?
The format that a document or piece of evidence was created in sometimes isn’t necessarily one that can be used to review it or present it in. For example, an image that contains text will not by default appear on your eDiscovery platform’s search engine when you search for that text. So some stages of the eDiscovery process–especially document review and production–require files to be modified, and thus changed from their native format into a “reasonably usable” format.
This happens on a regular basis, as electronic files in eDiscovery have to be searched for and reviewed. In the example of the image of text, platforms like GoldFynch will perform a process called OCR to extract the text and make it searchable. This process creates a derived file that has the text extracted. GoldFynch will keep track of both the original ‘native’ file and the ‘derived file’.
Keeping track of native and derived files like GoldFynch does becomes important in the eDiscovery process for a number of reasons:
- Native files are the ‘original’ document, which can be validated as legally permissible evidence
- During the conversion process, or due to the difference in format, some of the file’s data may be modified or lost entirely
- The ‘metadata’ of the file–the information about the file like when it was created or when it was last accessed–is often lost
- In the case of converting files that are ‘connected’ to each other (often known as a ‘family of files’ with ‘parent’ and ‘child’ files) like an email and its attachments, the attached ‘child’ files may not get carried across and linked with the modified ‘parent’ email file
So requests for documents in their native format are not uncommon either. Unfortunately, it’s not always easy to get hold of information in its native format. For example, it’s harder than you’d think to export emails from services like Yahoo and Outlook, and it can be quite a task to walk your client through the process (or to go through it yourself.) In fact, if a client doesn’t archive their information, it’s possible that the original files in their native format have been deleted and are impossible to get a hold of.
Though files aren’t always required in their native format, when they are it usually isn’t the best time to have to go hunting for the originals–at the least it will require a couple of searches through your client’s files, and much more commonly, it will take a number of phone calls and emails back and forth with them.
Does that mean I have to maintain multiple copies of every file for different formats?
Luckily, no. the right eDiscovery software will give you access to files in their native formats, while also letting you carry out functions like redacting and placing Bates stamps without requiring you to have multiple copies of the same file.
Take eDiscovery platform GoldFynch, for example. Because of its robust production system, it allows you to choose exactly how you want your files produced or exported. It lets you:
1) Set overall production formats including the native format:
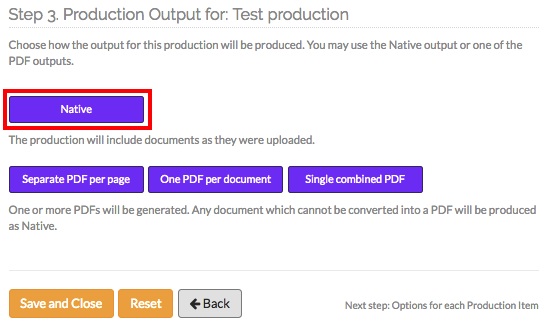
The various formats in which GoldFynch can produce documents
2) Selectively flag individual files to be produced in their native formats in PDF productions. These can be from anywhere in your case, even the middle different folders:
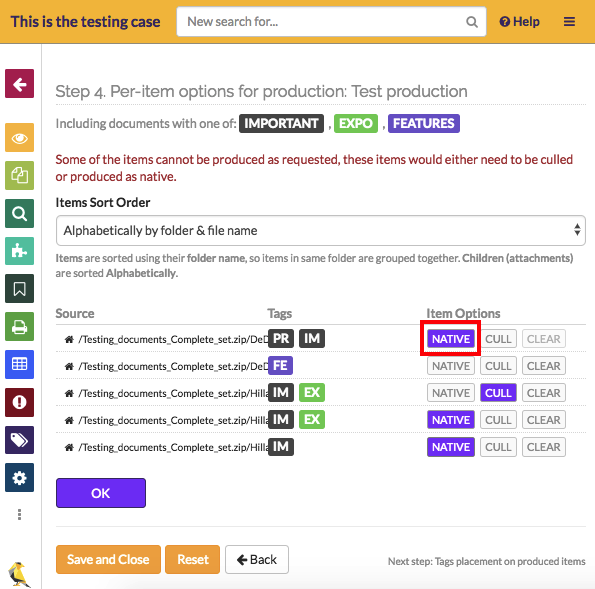
The files marked ‘native’ will not be assigned Bates stamps, tag stamps, or have their redactions included in the final produced files. Files marked ‘cull’ are omitted from productions completely
3) Place redactions on documents while still being able to revert to the native format during production
4) Place Bates stamps and custom ‘tag’ stamps on documents during production. Files that are flagged for being produced in the ‘native’ state are not considered by the number, so the numbering remains unbroken across stamped documents. Additionally, it allows you to position the stamps (e.g. in the bottom-left corner for all Bates stamps, and bottom-right corner for all files tagged ‘Important’) and add ‘padding’ to the numbering (e.g. “BA00013,” “BA00014,” “BA00015,” etc.)
5) Share productions directly from your GoldFynch account so that you can keep track of who you have shared them with and when they downloaded or opened the files
6) Access and download a ‘production log’ of productions to see the files it contains, and for each file:
- whether it is in the native or non-native format
- whether it contains redactions
- the number of pages in the file
- the bates range assigned to the pages in the file
7) Exclude entire sets of files from productions ‘inverted’ tags
8) Request custom production operations for specific load file formats or ingestion into other eDiscovery software like Relativity or Concordance
Learn more about producing files in GoldFynch here, and best practices for working with native-format documents and load files here.
Many of GoldFynch’s other features compliment the way it handles productions
1) It is cloud-based, which means that all your data is hosted online, so you can access it from anywhere, and do not have to carry every version of every document with you
2) It automatically carries out OCR (Optical Character Recognition) on your files when you upload them–an essential feature for the discovery process that involves processing images (and images of documents) to extract keywords, dates, and text from them, making them searchable by the platform’s search engine. (Note: it’s possible to still access them in their native format in which the OCR process hasn’t been carried out)
3) On the off-chance that an uploaded file’s format is not readable by GoldFynch, you will still be able to download it in the native format and use the relevant software to open it (since it will be identical to the file uploaded)
If you’d like to learn more about GoldFynch, check out:
For more about streamlining your small law firm’s eDiscovery, check out these articles:
- 8 Common eDiscovery Mistakes Your Small Law Firm May be Making
- 16 Have-to-Know Questions to Simplify eDiscovery for Your Small Law Firm
- 7 Easy eDiscovery Fixes to Save Money for Your Small Law Firm
- 5 Steps to Fixing the eDiscovery Search Mistakes Your Small Law Firm Might Be Making
- Learn how you can custom stamp the files in your production
- What’s the Difference Between PDF, DOCX, TXT and RTF files in eDiscovery?
- How to Find Out When a Document Or Web Page Was Created